1. 딥러닝 심층신경망(DNN) 모델 프로세스
① 라이브러리 임포트(import)
② 데이터 가져오기(Loading the data)
③ 탐색적 데이터 분석(Exploratory Data Analysis)
④ 데이터 전처리(Data PreProcessing) : 데이터타입 변환, Null 데이터 처리, 누락데이터 처리, 더미특성 생성, 특성 추출 (feature engineering) 등
⑤ Train, Test 데이터셋 분할
⑥ 데이터 정규화(Normalizing the Data)
⑦ 모델 개발(Creating the Model)
⑧ 모델 성능 평가
import tensorflow as tf
from tensorflow.keras.models import Sequential
from tensorflow.keras.layers import Dense, Dropout
tf.random.set_seed(100)
#하이퍼파라미터 설정
batch_size = 16
epochs = 20
X_train.shape , y_train.shape
A. 이진분류 DNN모델 구성
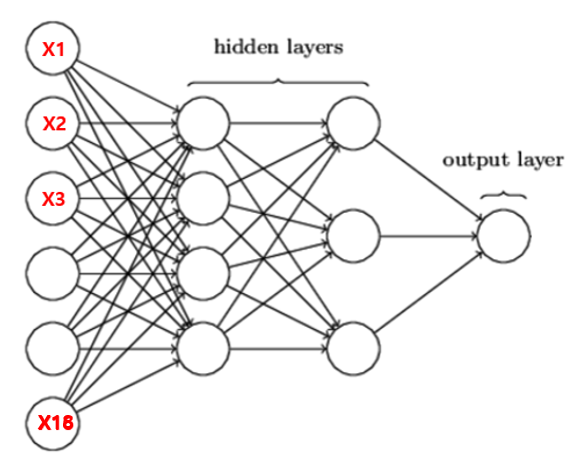
[문제] 요구사항대로 Sequential 모델을 만들어 보세요.
# Sequential() 모델 정의 하고 model로 저장
# input layer는 input_shape=() 옵션을 사용한다.
# 39개 input layer
# unit 4개 hidden layer
# unit 3개 hidden layer
# 1개 output layser : 이진분류
model = Sequential()
model.add(Dense(4, activation='relu', input_shape=(39,)))
model.add(Dense(3, activation='relu'))
model.add(Dense(1, activation='sigmoid'))
#모델 확인
model.summary()

1.모델 구성 - 과적합 방지
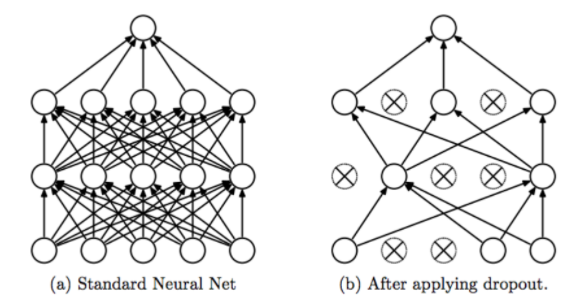
model = Sequential()
model.add(Dense(4, activation='relu', input_shape=(39,)))
model.add(Dropout(0.3))
model.add(Dense(3, activation='relu'))
model.add(Dropout(0.3))
model.add(Dense(1, activation='sigmoid'))
model.summary()

2.모델 컴파일 – 이진 분류 모델
model.compile(optimizer='adam',
loss='binary_crossentropy',
metrics=['accuracy'])
- 모델 컴파일 – 다중 분류 모델 (Y값을 One-Hot-Encoding 한경우)
model.compile(optimizer='adam', loss='categorical_crossentropy', metrics=['accuracy'])
- 모델 컴파일 – 다중 분류 모델 (Y값을 One-Hot-Encoding 하지 않은 경우)
model.compile(optimizer='adam', loss='sparse_categorical_crossentropy', metrics=['accuracy'])
- 모델 컴파일 – 예측 모델 model.compile(optimizer='adam', loss='mse')
# 앞쪽에서 정의된 모델 이름 : model
# Sequential 모델의 fit() 함수 사용
# @인자
### X, y : X_train, y_train
### validation_data=(X_test, y_test)
### epochs 10번
### batch_size 10번
3.모델 학습
[문제] 요구사항대로 DNN 모델을 학습시키세요.
model.fit(X_train, y_train,
validation_data=(X_test, y_test),
epochs=10,
batch_size=10)
B. 다중 분류 DNN 구성
- 13개 input layer
- unit 5개 hidden layer
- dropout
- unit 4개 hidden layer
- dropout
- 2개 output layser : 이진분류
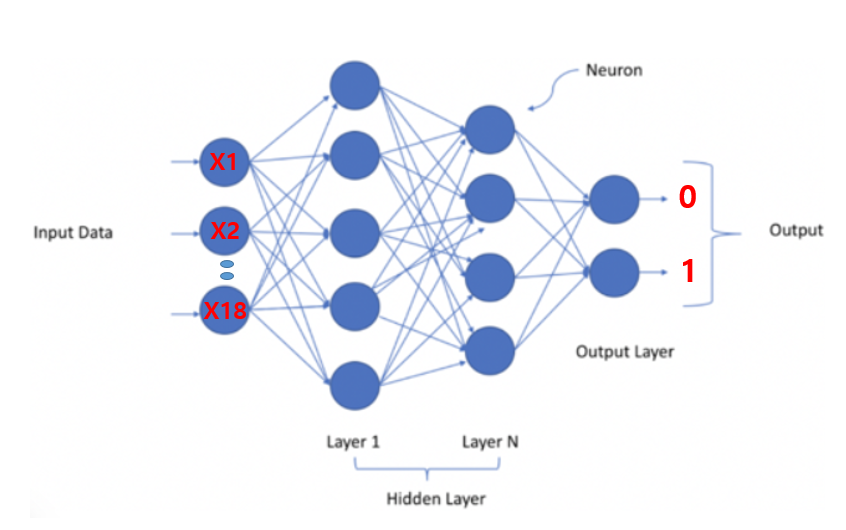
# 39개 input layer
# unit 5개 hidden layer
# dropout
# unit 4개 hidden layer
# dropout
# 2개 output layser : 다중분류
model = Sequential()
model.add(Dense(5, activation='relu', input_shape=(39,)))
model.add(Dropout(0.3))
model.add(Dense(4, activation='relu'))
model.add(Dropout(0.3))
model.add(Dense(2, activation='softmax'))
1. 모델 확인
model.summary()

2. 모델 컴파일 – 다중 분류 모델
model.compile(optimizer='adam',
loss='sparse_categorical_crossentropy',
metrics=['accuracy'])
3. 모델 학습
history = model.fit(X_train, y_train,
validation_data=(X_test, y_test),
epochs=20,
batch_size=16)
Callback : 조기종료, 모델 저장
from tensorflow.keras.callbacks import EarlyStopping, ModelCheckpoint
# val_loss 모니터링해서 성능이 5번 지나도록 좋아지지 않으면 조기 종료
early_stop = EarlyStopping(monitor='val_loss', mode='min',
verbose=1, patience=5)
# val_loss 가장 낮은 값을 가질때마다 모델저장
check_point = ModelCheckpoint('best_model.h5', verbose=1,
monitor='val_loss', mode='min', save_best_only=True)
history = model.fit(x=X_train, y=y_train,
epochs=50 , batch_size=20,
validation_data=(X_test, y_test), verbose=1,
callbacks=[early_stop, check_point])
모델 성능 평가
성능 시각화
plt.plot(history.history['accuracy'])
plt.plot(history.history['val_accuracy'])
plt.title('Accuracy')
plt.xlabel('Epochs')
plt.ylabel('Acc')
plt.legend(['acc', 'val_acc'])
plt.show()
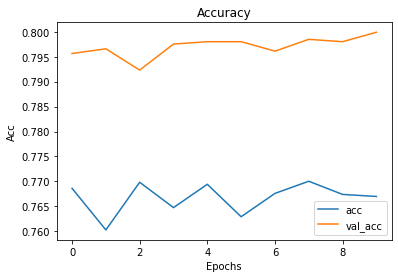
성능 평가
from sklearn.metrics import accuracy_score, precision_score, recall_score, f1_score
from sklearn.metrics import classification_report
pred = model.predict(X_test)
pred.shape
y_pred = np.argmax(pred, axis=1)
# 정확도 80%
accuracy_score(y_test, y_pred)
# 재현율 성능이 좋지 않다
recall_score(y_test, y_pred)
# accuracy, recall, precision 성능 한번에 보기
print(classification_report(y_test, y_pred))
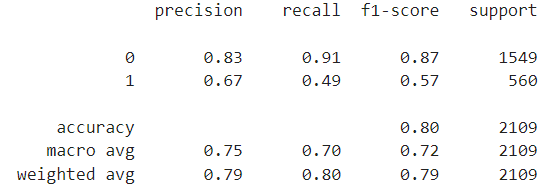
=> 성능 향상
- 성능향상 할수 있는 방법은 여러가지 있습니다.
- DNN 하이퍼 파라미터 수정하면서 성능향상이 되는지 확인
- 데이터 줄이거나 늘리거나, Feature(컬럼)을 늘리거나 줄이거나 하는 식의 Feature Engineering 방법
Feature Engineering 통한 성능향상
- 불균형 Churn 데이터 균형 맞추기 : OverSampling, UnderSampling
- OverSampling 기법 : SMOTE(Synthetic Minority Over-sampling Technique)
'AI' 카테고리의 다른 글
| TensorFlow vs Keras (0) | 2024.03.22 |
|---|---|
| 라이브러리 vs 프레임워크 (0) | 2024.03.22 |
| 파이토치 (0) | 2024.03.11 |
| CNN / RNN / LSTM (0) | 2023.11.02 |
| 앙상블 (0) | 2023.10.31 |



